ZIPSLICER is available on GitHub and on PyPI. Intended audience: individuals who find themselves working with torch checkpoints with size on the order of available CPU RAM.
Introduction
Successful software design and satisfactory performance have underpinned PyTorch’s rise to the top as the premier deep learning (hereafter DL) framework over the past 5 years. From this simple observation we can proceed to notice that the majority of DL models start the post-training part of their lifecycle as a monolithic pytorch checkpoint produced by a simple torch.save() call.
There is no shortage of infra problems with large ML models these days. Even if we take training out of the picture, one transient challenge which often arises in ML engineering is executing transformations on the trained checkpoints. Naturally, to do anything with the checkpoint at all, you need to be able to access – load – it. With the convenient and well-supported torch.load() mechanism, even very simple transformations like sharding the tensors and direct casting of weight datatypes consume some multiple (usually 4, due to single-precision floating point still being the only well-supported format on many CPUs) of the checkpointed model’s parameter count in RAM bytes. This 4x size multiplier is in stark contrast with the compressed in-VRAM size of these models after they are optimized for inference, which could be as low as 4 bits per parameter, with the usual being around 8 bits per parameter. When one works with large checkpoints, such as Galactica-120B, RAM consumption starts to become a major problem. In well-funded companies and institutions this problem is usually avoided through one of the few available options:
- Renting a high-RAM server in the cloud just for this specific part of the ML engineering pipeline;
- Distributing checkpoints as a list of shards (usually with an adhoc sharding config or scheme, and with each shard being quite large as well) – so each shard ends up being a separate pytorch checkpoint;
- Or even by replacing the native torch storage format with something else, such as the novel
safetensorsformat by huggingface.
One could, of course, dismiss this as an issue concerning only the small circle of ML engineers whose professional tasks involve large language models. But I don’t think we should underestimate the proliferation of these large models into adjacent applied fields of science, entertainment and such; and while this could be downplayed as a mere tech demo, popularity of projects like FlexGen points to the popular demand for optimizing the foundations of this usecase.
The monolithic checkpoint problem in the age of LLMs
Here are some obvious inadequacies in realistic scenarios of working with checkpoints today:
Often enough you need to spin up multi-gigabyte checkpoints from huggingface and other sources – and not just for inference, where you at least have access to a decently-sized cluster provided by your employer, but to execute some transient model transformations in preparation for that as well.
Model conversion pipelines are often implemented in such a way as to require storing the complete checkpoint state at RAM at least once – even though in principle this shouldn’t be necessary, as the model is already stored on the non-volatile storage.
Many DL models, and specifically transformer neural networks, enjoy a very uniform layered architecture supporting large batch sizes: you can even run inference layer-by-layer, if your runtime engine supports it. And considering the industry demand for large-batch offline inference, there is a practical angle to it as well.
The naive implementation of the abovementioned runtime, while possible, suffers from the basic problem inherent to the current design of pytorch: the checkpoint writer uses large byte blobs for persisting the underlying tensor storage, and the default checkpoint loader has to load entire storage blobs even if you only need a few tensors.
Clearly, the fundamental bottleneck here lies in the torch.save() and, more importantly for most tasks, in torch.load() functions – our hypothetical incremental model execution engine’s RAM savings would be made obsolete by the calls to stock torch.load().
Can we write an alternative implementation of torch.load() (And torch.save(), eventually) as an External memory algorithm ?
While it is true that pytorch checkpoint is a pickle – a native Pythonic format for persisting stateful instances of objects – packaged in a zipfile, and given the general-purpose nature of pickles this could greatly complicate the exercise we are getting to. Thankfully the typical torch checkpoint is a much simpler dictionary-like object called state_dict. Now we can assume a specific, but very common and officially recommended case of storing your model’s parameters as a state_dict – which is simply a pickled Python OrderedDict with keys corresponding to name dependent on the position of the parent nn.Module in the hierarchy and the value is the tensor data (or plain extra state). This simplifies the problem, leading to a natural API for incremental tensor loading: we can provide a lightweight ordered dictionary of references to tensors stored in the checkpoint and materialize them by reading just enough of the zip file, when the users accesses the associated value. We can also provide tensor metadata by key without loading the whole tensor from disk.
Naturally, this approach would require a customized pickle reader and tensor- and storage- loader. I took this task head-on, and in the next section I present the short rundown of problems I encountered on the way.
The fine structure of a Torch checkpoint
We already noted that the checkpoint is a pickle – but it is also packaged in a standard zipfile.
Surely many people have tried to open a torch checkpoint with zip archiver; what they saw was a list of files with opaque names, one of them called “data.pkl”:
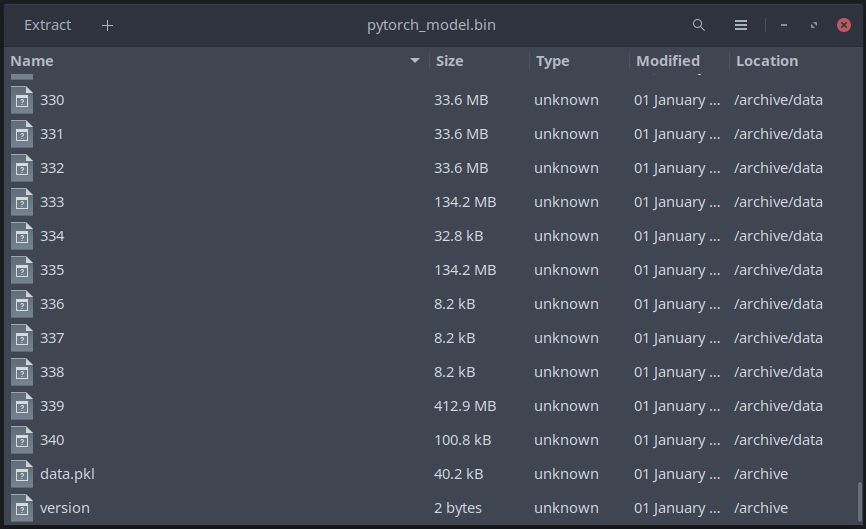
My first impulse, driven by curiosity, was to jump into torch serialization source straight from my editor, which is possible due to the opensource nature of PyTorch. I saw a nest of functions, some of which were used for an older folder-based data format. After some soul-searching, I decided that the way forward was to generously insert print() statements into important functions related to tensor assembly and unpickling; a couple of hours later I had a working dumper of function calls that are usually executed to construct tensors of the state_dict.
Using this dumper code and the base pytorch serialization source code as a template, I extracted the function tree of the torch.load() into a standalone source tree, which later became a part of zipslicer’s source code. Crucially, I patched the pickler to replace function calls which create massive storage objects and tensor objects with emitters of lightweight metadata.
This metadata is stored in the zipslicer object to be used as a direction for my relatively novel contribution – a function that is able to correctly compute the required offset to get the portion of storage that is enough to represent the tensor, and actually does the work of navigating the binary zipfile stream in constant time to read it and return a tensor. The initial simple solution of using the default pytorch storage objects wasn’t cutting it, due to many tensors being coalesced into a single torch storage by torch.save(), at least in the checkpoints I was interested in - defeating the point of incremental loading. And while, in theory, there is a possibility of rare tensor types (such as pytorch native quantized tensors, or non-contiguous tensors) being incompatible with this simple, fast approach; and it also depends on the zipfile being uncompressed (which is the default in torch.save()) – for now, my exhaustive tests for the checkpoints I have weren’t met with incompatibility.
This functionality – a drop-in replacement for torch.load() for many compatible checkpoints – is packaged in a high-level zipslicer.load() call, returning an OrderedDict-like LazyStateDict which implements the logic described above on the fly.
This is how the initial version of ZIPSLICER came to be. Hopefully in the next versions we will support overlay checkpoints (seamlessly multiplexing many checkpoints into one in a git-sourcetree-like fashion) and develop our own torch.save(). For now, if you want to save a large checkpoint you can simple save it as a list of smaller shards.
I expect this release to make practical work with large deep learning models more approachable for students and under-resourced researchers alike.
The high-level API of ZIPSLICER: zipslicer.load()
| |
See this example in the GitHub repo
Call to collaboration
This is the first alpha-release of the library. Right now it works in a few scenarios of my personal interest, and there is a small-ish test suite and an exhaustive compatibility tester script. Any help at validating the loader for a wider range of usecases (with the provided read-only tester script) is welcome.
The author also expresses interest in supplying HF safetensors with an efficient conversion script based on ZIPSLICER.
Honorable mentions
- zipcraft - for demonstrating easy addressing into an uncompressed zipfile
- HDF5 - for showing how it was done by our fathers
- Safetensors - for aspiration of simplicity, with a tint of rust
- indexed_zstd - for saving Earth, one bit at a time
- indexed_gzip - for compression of what we have
- Seeking-optimized ZIP - for aspiration to compress more